Learn About Data Size Reduction Techniques

As the amount of data processed grows exponentially each year – society deals with the problem of how to keep all that data stored. For almost as long as humans have dealt with data, we have also dealt with the issue of storing it in a form that is not only reliable but also condensed.
Data Reduction techniques are methods that one can use to preserve data in a reduced or condensed form but without any loss of information or fidelity. In today’s world, where networks carry so much of our data, reducing data size is important, not just for condensing its storage footprint, but also to save on network bandwidth costs.
In the current climate, with so many businesses having their employees work from home, this challenge has taken on greater urgency as data increasingly gets transmitted over WiFi and home networks – which are limited in their bandwidth.
In today’s world, where networks carry so much of our data, reducing data size is important, not just for condensing its storage footprint, but also to save on network bandwidth costs.
Types of Data Reduction
Data reduction has been accomplished over the years, in many forms. The Morse code, for example, introduced back in 1838 was an early attempt to encode alphabets as shorter codes. We will quickly go over a few techniques – working our way from traditional compression methods to more current de-duplication techniques.
Compression Software
This is an obvious technique most people think of in the context of data reduction. After all, so many of us are familiar with tools such as GZip and WinZip – which serve to reduce data size. But it is perhaps interesting to many that software compression also comes in multiple varieties.
1. Lossy Compression
The type of compression used for multimedia files is called Lossy compression. For instance, when you take a photograph in RAW format and convert that to a jpeg, there is a loss of data. The loss is not easily discernible to the naked eye, but it manages to shrink the size of the file considerably. Since this takes away very little from the user experience – it is a practical way to accomplish data reduction on digital images. Similarly, music recorded live will generate files that are much larger than the mp3 files that you may listen to later. During conversion, a lot of sound frequencies that are not in the human audible range can be safely removed – thus reducing the size of such files significantly. So, such compression, while lossy – has no negative impact on the final analysis.
2. Lossless Compression
Data files on the other hand are a different matter altogether. A change of even one bit of data in the file can render the file unusable or corrupt. Worse, it could alter the information within the file in a dangerous way. Lossy compression cannot be used with data files. You need lossless compression techniques.
Lossless compression works by looking for similarities in segments of data and then unique-ing them out using references.
Let’s take an example and see how lossless compression works.
Read: Data loss may cost you more than a data backup solution
We’re using colored blocks, but pretend they are strings. The Blue strings labeled B are all identical. Similarly, the yellow strings labeled Y are all identical. And the red strings labeled R are all identical.
So, we can take the long string and easily represent it as

And that’s roughly how compression works.

Do you have specific requirements or enterprise needs?
Data Deduplication
Compression techniques are quite old and date back to the 1940s. Around the beginning of the millennium, however, a new type of data reduction technique caught everyone’s fancy – data deduplication.
1. File-level data deduplication
In its earliest and simplest form, data deduplication simply meant saving only one copy of a set of identical files – instead of keeping separate copies. So, in a data repository, if more than one instance of a file was found, only a single instance would be maintained and a database would be updated to record the fact that multiple instances of this file – perhaps in different folders, or in the possession of different users would all point to the first, single record of the file known to the data repository.
The process of determining that two files were identical would usually involve using a hash function to compute a unique signature for the file. MD5 was a popular hashing function and has since been replaced with SHA-1 or similar algorithms which reduce the chance of collisions.
2. Block-level data deduplication
File-level data deduplication was effective but in a limited way. Changing a file ever so slightly to create a new version of it – would mean it would compute to a different hash and would therefore be stored as a completely separate file. So, the gains in storage savings and network bandwidth reduction were fairly minimal.
File-level deduplication soon fell out of favor as block-level deduplication algorithms came into vogue.
Think of block-level deduplication as software compression’s big brother. Where compression looks for identical byte sequences in a small file buffer, de-duplication looks for identical byte sequences through a large database of hashes it maintains.
Let’s consider an example with 3 files – A, B, and C.
For convenience, let’s assume each is comprised of 3 chunks.
Block-level deduplication works by computing a ‘hash’ for each chunk. Think of the ‘hash’ as being a unique signature or fingerprint of the chunk. Here again, algorithms like MD5 or SHA1 are employed to compute these hashes – which basically is a unique representation of the file. If 2 hashes are found to be the same, one can then be certain that both chunks are identical.
So, let’s play out this scenario. In this example, if a chunk’s hash is unique and/or seen for the first time, it gets moved to the data repository.
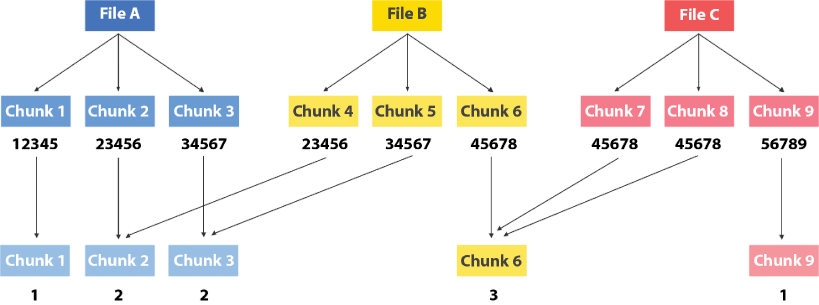
- Chunk 1 has a hash of 12345. Not seen before – so Chunk1 goes into the backup storage.
- Chunk 2 has a hash of 23456. Again – not seen before – so Chunk2 goes into backup storage.
- Chunk 3 has a hash of 34567. Not seen before – so Chunk 3 goes into backup storage. So far so good.
- Chunk 4 – has a hash of 23456. Wait a minute! We’ve seen this has before. So, instead of writing the chunk once again to backup storage, we simply go to our database catalog and increment a reference counter to indicated that Chunk 2 was seen twice.
- Chunk 5 – has a hash of 34567. Also seen before! So, instead of writing the chunk to backup storage, we increment the reference counter on Chunk 3 to indicate that we’ve seen it twice.
- Chunk 6 – unique hash.
- Chunk 7 – same hash as Chunk 6! Increment that reference counter!
- Chunk 8 – same hash as Chunk 6 again! Increment that reference counter again. Chunk 6 has now been seen 3 times.
- Chunk 9 – unique hash
Now – if you notice we’ve recorded considerably fewer data to the data repository than the original data size. We’ve instead updated our database catalog to show that some chunks showed up several times. So – no loss of data, but considerable savings in storage.
The Downside of Block Level Data Deduplication
While block-level deduplication looks awesome in theory, in practicality it can come with some serious downsides.
Let’s look at it with an example.
For simplicity, we’ll consider a single file with the following sentence in it.
Using the approach seen in the previous slide, we’ll break the file into fixed size chunks. Because it’s a small file, we’ll use 8 bytes as our fixed chunk size. Let’s see how the data will look, once chunked up.

Now let’s assume a change is made. We insert the word ‘NOT’ mid-way into the file. So the contents of the file now change to look as follows.
Using the same chunk size as before, let’s see what the data would look like once chunked up.

See how many of the chunks are now different than before? Just inserting a few bytes mid-way in the file essentially pushed all the content out enough that it completely upset the chunk-hashing mechanism that looked so good on the previous slide.
Variable-Length Block Level Data Deduplication
The answer is variable-length block-level deduplication. Let’s see how it works.
Unlike fixed-length blocks, with variable length blocks, what we do is not fix the size, but instead, fix a repeated character or pattern. Anytime the software sees that familiar character or pattern, it starts a new block.

We’ll use the same sentence as before for our example. And for the repeated pattern, we’ll use the character ‘E’. Whenever we see an E, we’ll start a new block. So the block sizes may vary – they may be really small or sometimes a bit larger, but they’ll always start with an E.
Let’s see how this approach plays out.
Let’s insert something into the file – the word NOT just like last time.
Let’s now use variable block lengths anchored around ‘E’ and see how many chunks really change from earlier. Just 1!

Much better.
A number of modern applications such as backup solutions make heavy use of de-duplication and in particular, of variable-length block-level de-duplication techniques.

Know-How It Works?
Data deduplication can be complex and is a subject of considerable research as mathematicians and computer scientists try to find better ways to reduce data size without losing information. In this blog, we’ve covered some basic methods of data reduction – which we hope were educational and informative.
If you have comments or anything you wish to add, please write to us at info@parablu.com with questions or opinions. We’d love to hear from you.



